Commits on Source (24)
-
Karim Ahmed authoredd8404024
-
Karim Ahmed authoredd9666f6e
-
Karim Ahmed authored
[AGIPD][CORRECT] Remove the default specification for caldb_root See merge request !994
1f3f348a -
b16026b2
-
35c2bcfd
-
Karim Ahmed authored248708c9
-
Karim Ahmed authored
[DOC] Updated documentations while preparing for DET calibration training See merge request !989
132079a3 -
8d3fa197
-
1b96322f
-
5ca049e8
-
2d3f03bf
-
a77f83e0
-
de7ef3e2
-
b816be12
-
af88f7ac
-
a13bd103
-
8b07d324
-
51a7d4b7
-
b074c2ea
-
0c2f1d8a
-
e60d0693
-
Philipp Schmidt authored074e8c14
-
Philipp Schmidt authored816db504
-
Philipp Schmidt authored1f6bbefa





Showing
- docs/operation/calibration_database.md 2 additions, 1 deletiondocs/operation/calibration_database.md
- docs/operation/detector_specific_troubleshooting.md 73 additions, 0 deletionsdocs/operation/detector_specific_troubleshooting.md
- docs/operation/myMDC.md 6 additions, 3 deletionsdocs/operation/myMDC.md
- docs/operation/troubleshooting.md 102 additions, 0 deletionsdocs/operation/troubleshooting.md
- docs/operation/webservice.md 30 additions, 2 deletionsdocs/operation/webservice.md
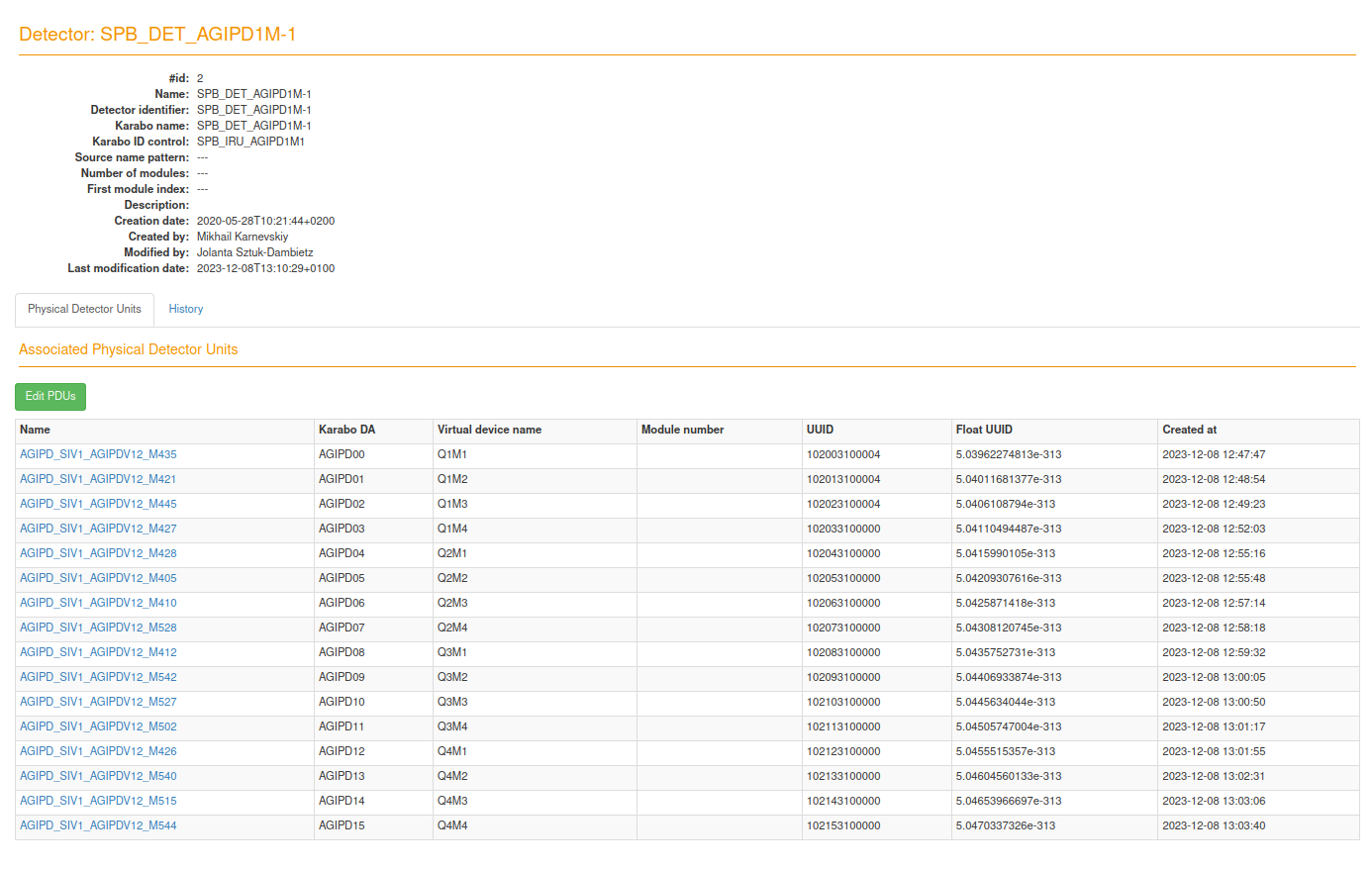
- docs/static/calcat/detector_mapping_edit.png 0 additions, 0 deletionsdocs/static/calcat/detector_mapping_edit.png
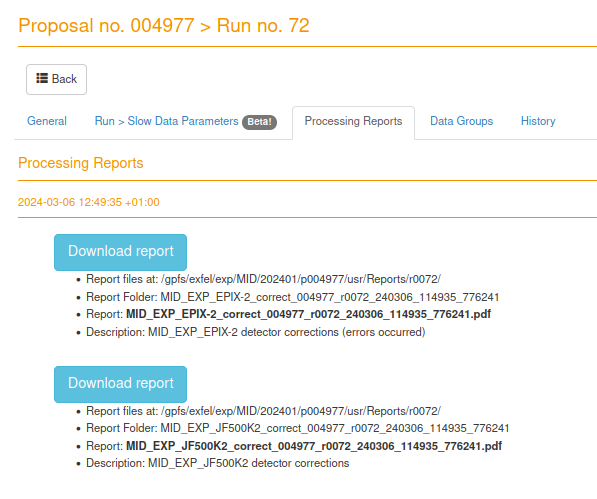
- docs/static/myMDC/processing_reports.png 0 additions, 0 deletionsdocs/static/myMDC/processing_reports.png
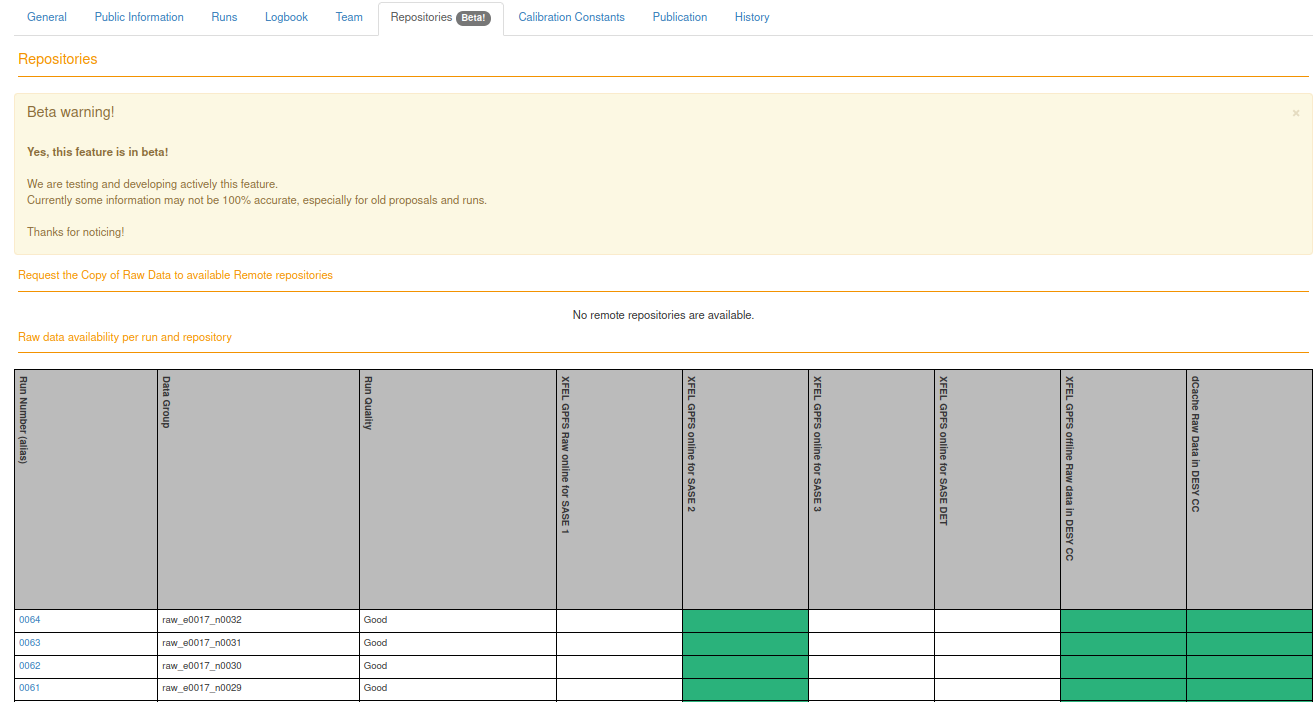
- docs/static/myMDC/repositories.png 0 additions, 0 deletionsdocs/static/myMDC/repositories.png
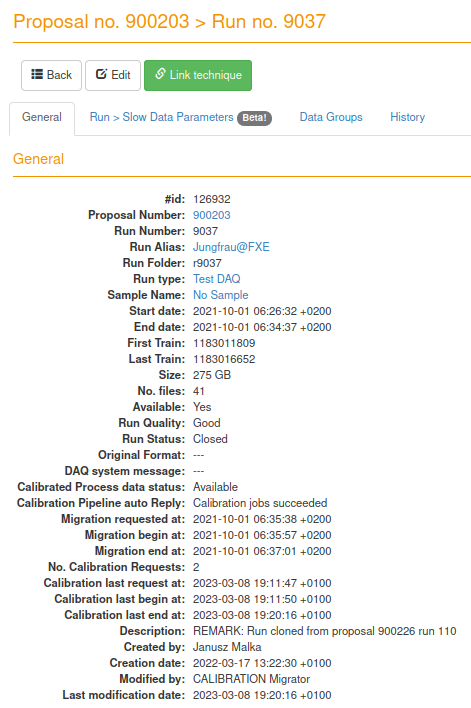
- docs/static/myMDC/run_72_general_status.png 0 additions, 0 deletionsdocs/static/myMDC/run_72_general_status.png
- docs/static/myMDC/run_9037_general_status.png 0 additions, 0 deletionsdocs/static/myMDC/run_9037_general_status.png
- docs/static/troubleshooting/gh2_25um_no_trains_to_correct.png 0 additions, 0 deletions.../static/troubleshooting/gh2_25um_no_trains_to_correct.png
- docs/static/troubleshooting/missing_data_second_gh2_module.png 0 additions, 0 deletions...static/troubleshooting/missing_data_second_gh2_module.png
- docs/static/troubleshooting/no_litframes.png 0 additions, 0 deletionsdocs/static/troubleshooting/no_litframes.png
- docs/static/troubleshooting/pending_jobs.png 0 additions, 0 deletionsdocs/static/troubleshooting/pending_jobs.png
- docs/static/troubleshooting/shutter_run_state.png 0 additions, 0 deletionsdocs/static/troubleshooting/shutter_run_state.png
- docs/static/webservice/job_monitor_log.png 0 additions, 0 deletionsdocs/static/webservice/job_monitor_log.png
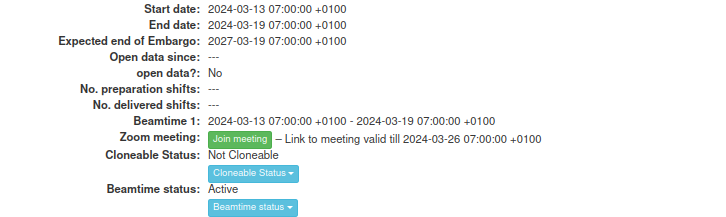
- docs/static/webservice/mymdc_active_proposal_5438.png 0 additions, 0 deletionsdocs/static/webservice/mymdc_active_proposal_5438.png
- docs/static/webservice/webservice_job_db.png 0 additions, 0 deletionsdocs/static/webservice/webservice_job_db.png
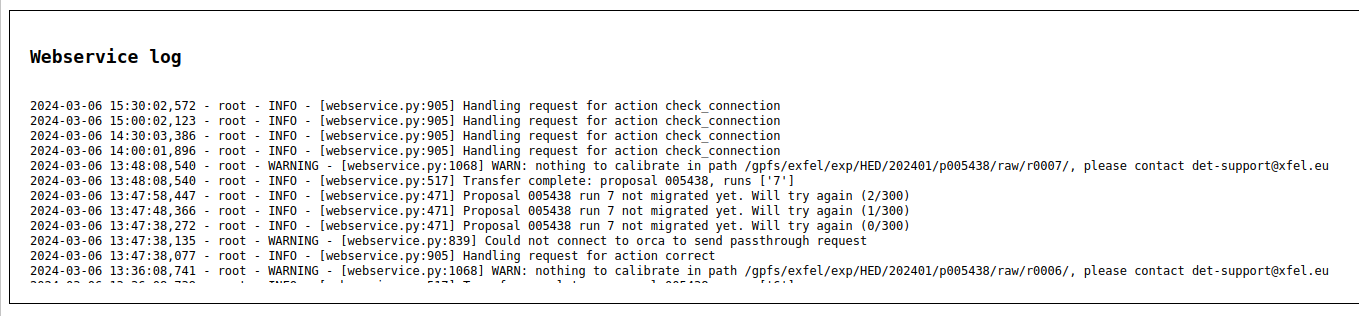
- docs/static/webservice/webservice_log.png 0 additions, 0 deletionsdocs/static/webservice/webservice_log.png
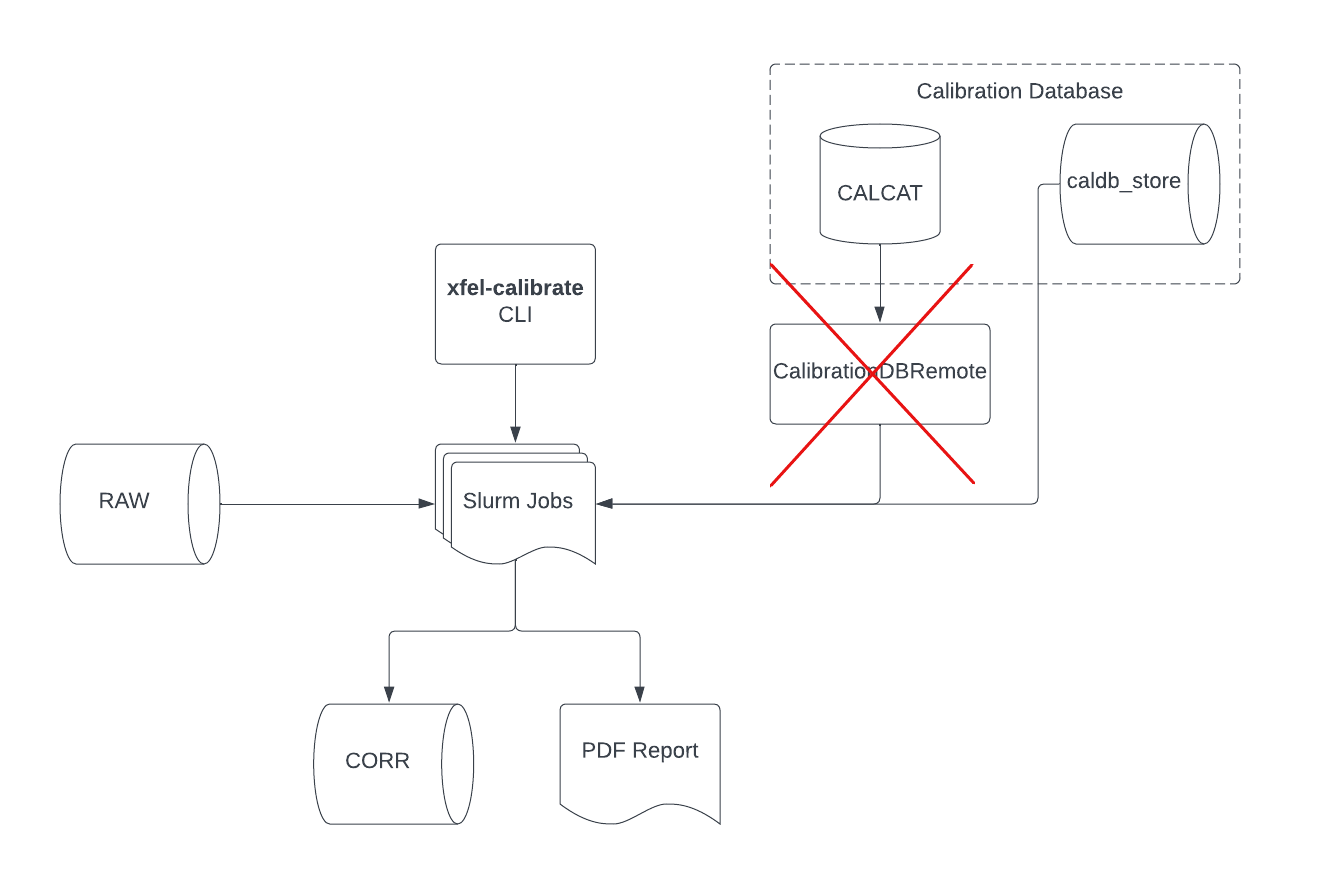
- docs/xfel-calibrate_cli_process_no_caldbremote.png 0 additions, 0 deletionsdocs/xfel-calibrate_cli_process_no_caldbremote.png
docs/operation/troubleshooting.md
0 → 100644
docs/static/calcat/detector_mapping_edit.png
0 → 100644
{kind=link}
196 KiB
docs/static/myMDC/processing_reports.png
0 → 100644
{kind=link}
71.8 KiB
docs/static/myMDC/repositories.png
0 → 100644
{kind=link}
69.1 KiB
docs/static/myMDC/run_72_general_status.png
0 → 100644
{kind=link}

111 KiB
{kind=link}
86.3 KiB
{kind=link}

26.7 KiB
{kind=link}
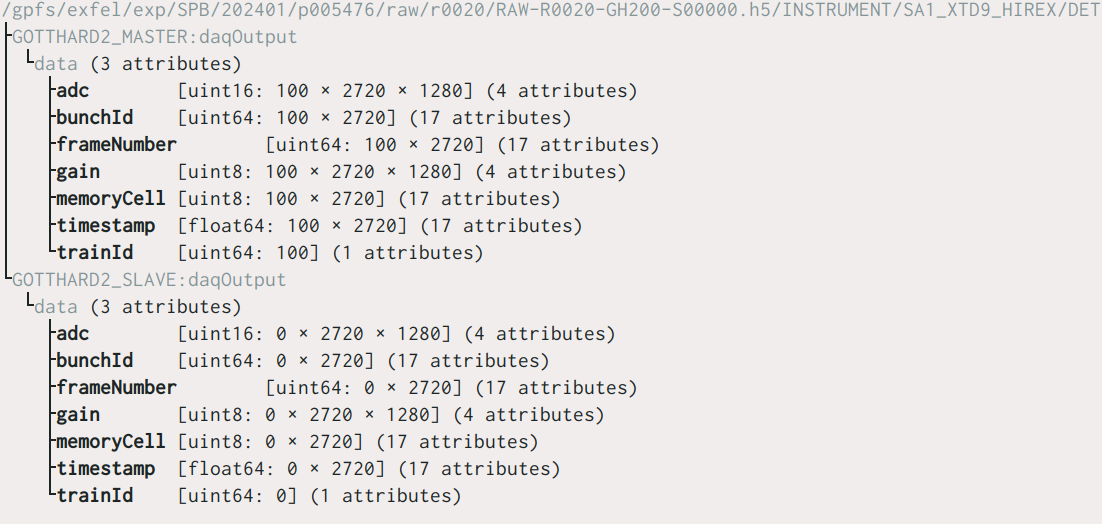
135 KiB
docs/static/troubleshooting/no_litframes.png
0 → 100644
{kind=link}
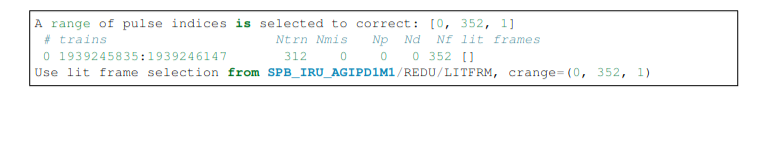
27.1 KiB
docs/static/troubleshooting/pending_jobs.png
0 → 100644
{kind=link}

211 KiB
{kind=link}
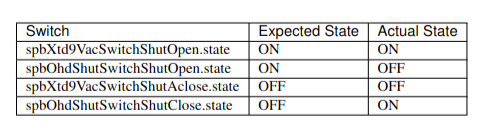
33.7 KiB
docs/static/webservice/job_monitor_log.png
0 → 100644
{kind=link}
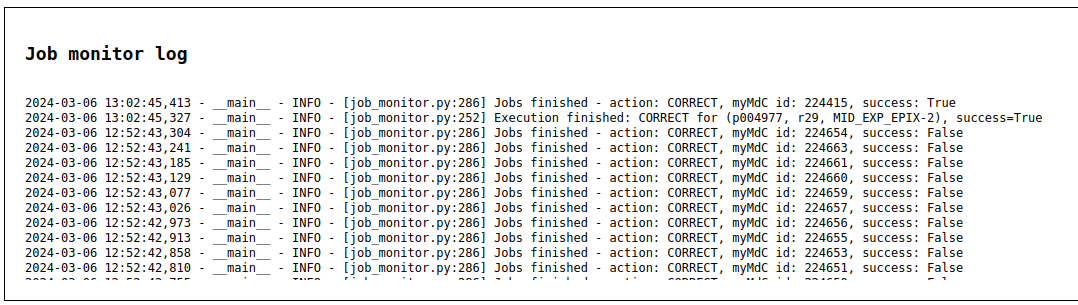
138 KiB
{kind=link}
36.4 KiB
{kind=link}
docs/static/webservice/webservice_log.png
0 → 100644
{kind=link}
139 KiB
{kind=link}
20.4 KiB